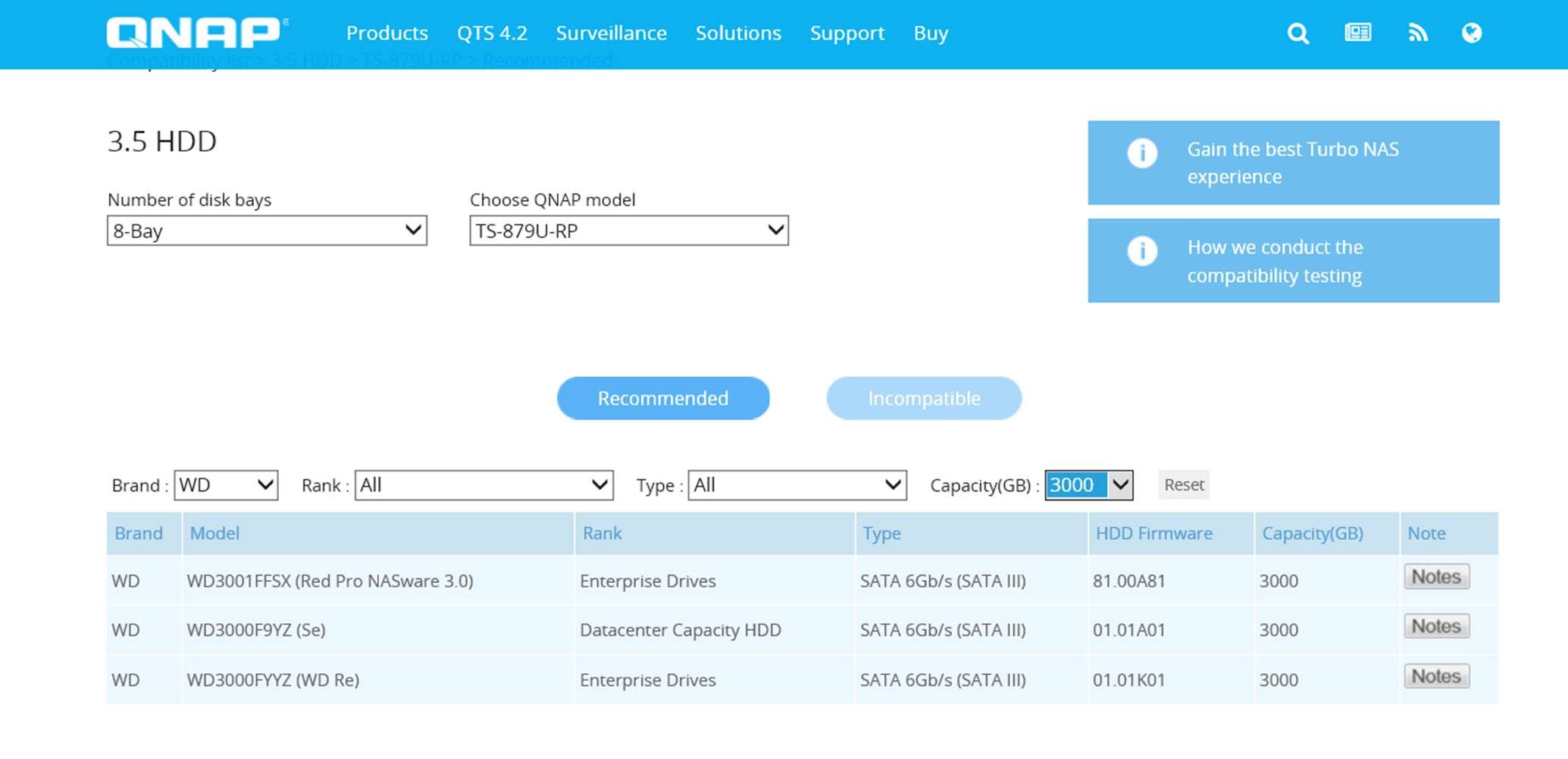
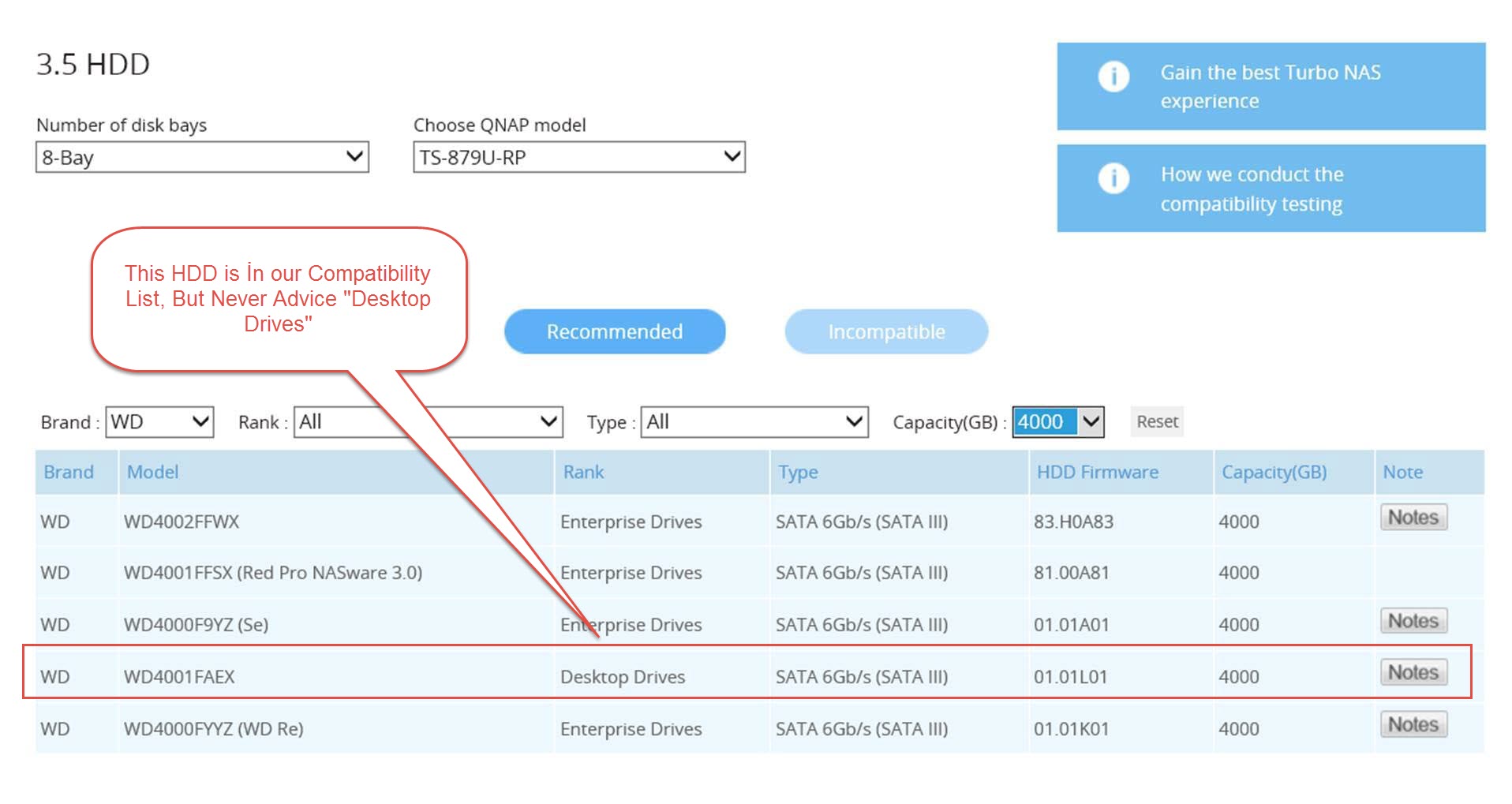
1 – Öncelikle, Satın Almayı Planlanladığınız HDD Mutlaka Uyumluluk Tablomuzda Olmalıdır;
https://www.qnap.com/i/en/compatibility/
2 –Ve Eğer Verileriniz Kritik İse, Seçeceğini HDD’lerin “Enterprise” or “Datacenter” Grubunda Olmasını Tercih Etmelisiniz;
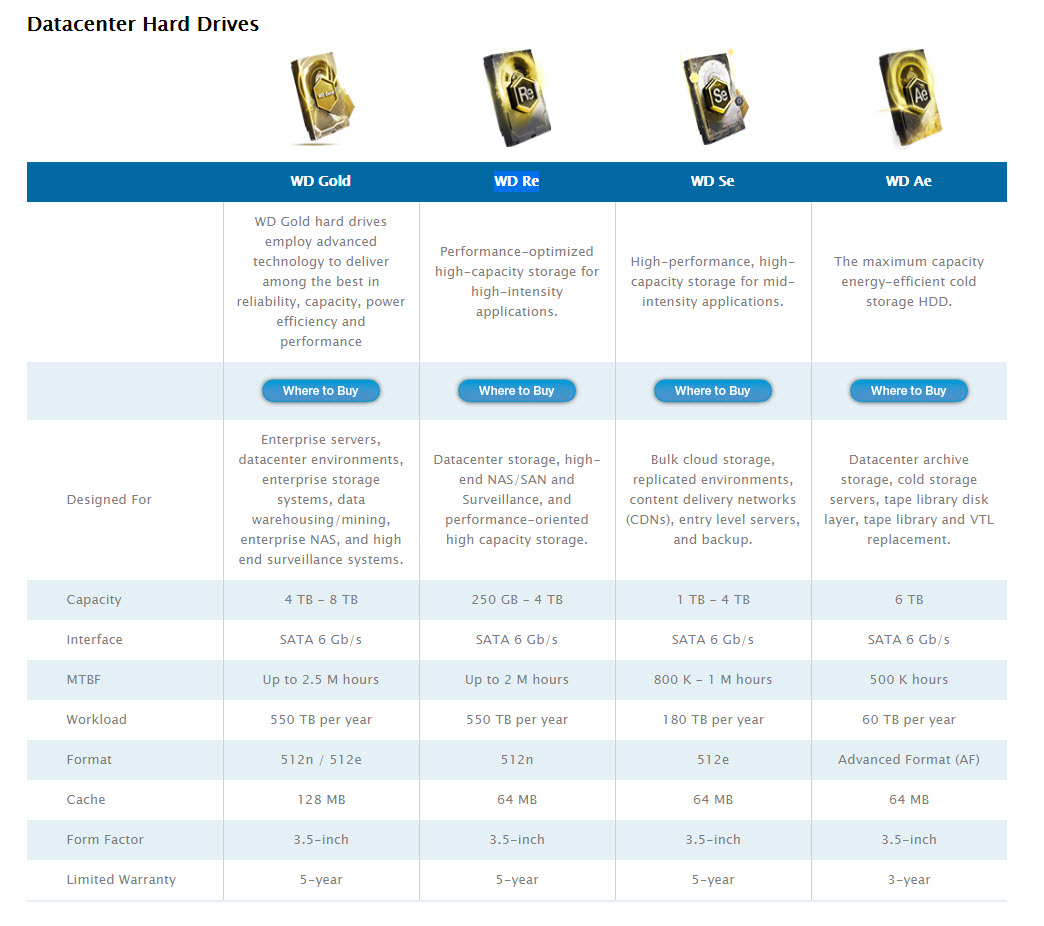
3- Senin Önereceğiniz HDD Nedir Diye Sorarsanız, Ben Western Digital’ın WD RED Pro Yada RE Modellerini Öneriyorum;
4 – HDD Stabilitesi Konusunda Aşağıdaki Siteyi Takip Edebilirsiniz;
www.backblaze.com
https://www.backblaze.com/blog/hard-drive-reliability-stats-q1-2016/

For Q1 2016 we are reporting on 61,590 operational hard drives used to store encrypted customer data in our data center. There are 9.5% more hard drives in this review versusour last review when we evaluated 56,224 drives. In Q1 2016, the hard drives in our data center, past and present, totaled over one billion hours in operation to date. That’s nearly 42 million days or 114,155 years worth of spinning hard drives. Let’s take a look at what these hard drives have been up to.
Backblaze hard drive reliability for Q1 2016
Below are the hard drive failure rates for Q1 2016. These are just for Q1 and are not cumulative, that chart is later.
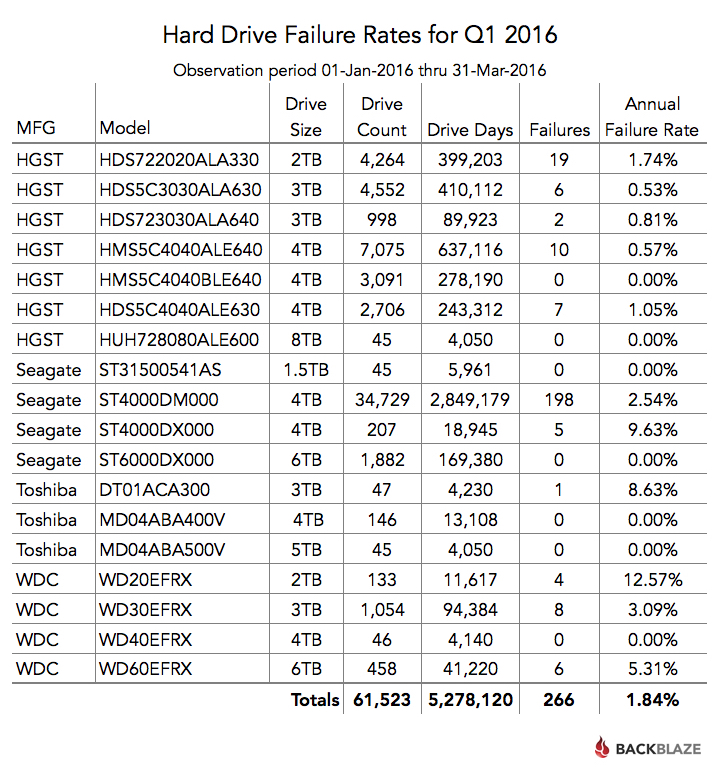
Some observations on the chart:
- The list totals 61,523 hard drives, not 61,590 noted above. We don’t list drive models in this chart of which we have less than 45 drives.
- Several models have an annual failure rate of 0.00%. They had zero hard drive failures in Q1 2016.
- Failure rates with a small number of failures can be misleading. For example, the 8.65% failure rate of the Toshiba 3TB drives is based on one failure. That’s not enough data to make a decision.
- The overall Annual Failure Rate of 1.84% is the lowest quarterly number we’ve ever seen.
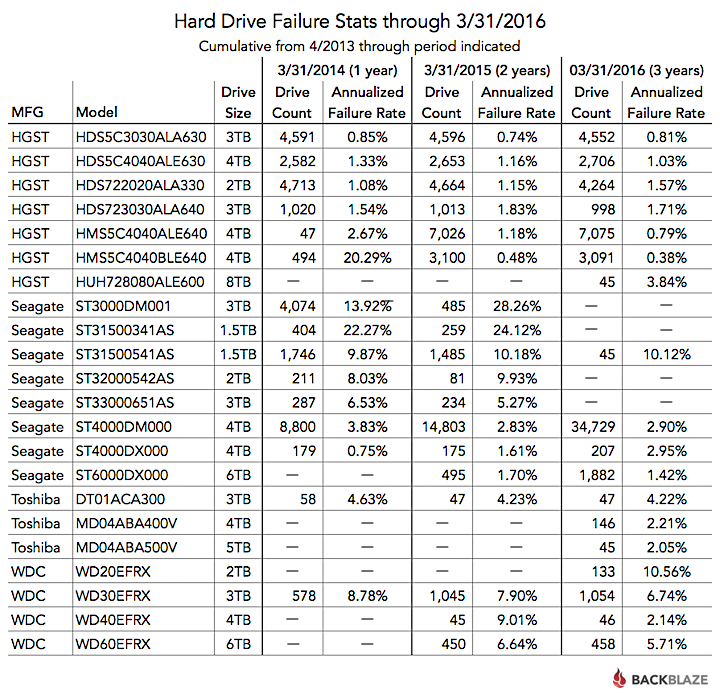
Cumulative hard drive reliability rates
We started collecting the data used in these hard drive reports on April 10, 2013, just about three years ago. The table below is cumulative as of 3/31 for each year since 4/10/2013.
One billion hours of spinning hard drives
Let’s take a look at what the hard drives we own have been doing for one billion hours. The one billion hours is a sum of all the data drives, past and present, in our data center. For example, it includes the WDC 1.0TB drives that were recently retired from service after an average of 6 years in operation. Below is a chart of hours in service to date ordered by drive hours:
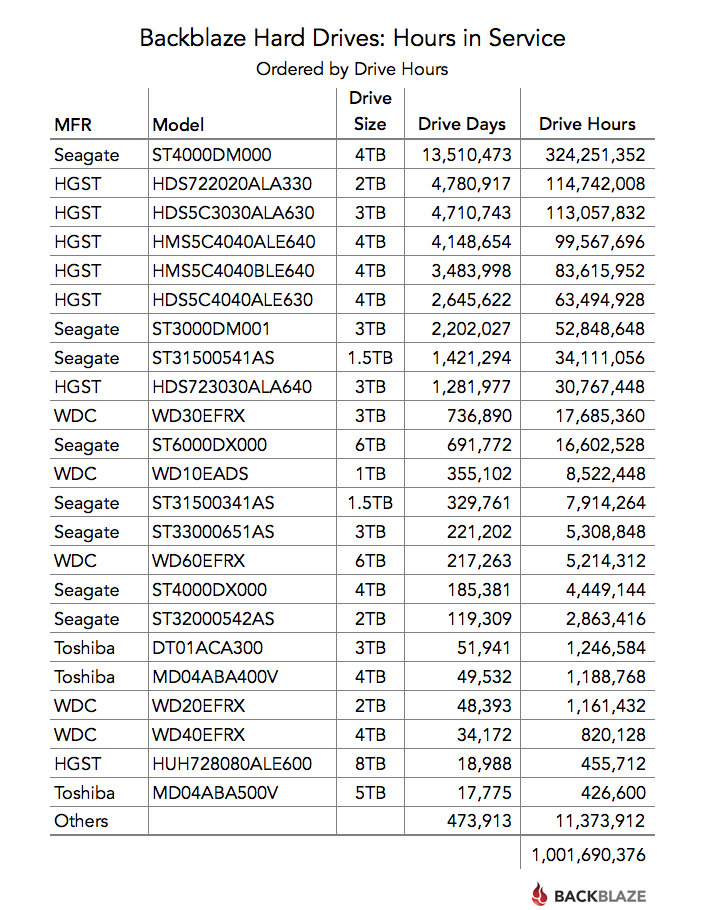
The “Others” line accounts for the drives that are not listed because there are or were fewer than 45 drives in service.
In the table above, the Seagate 4TB drive leads in “hours in service” but which manufacturer has the most hours in service? The chart below sheds some light on this topic: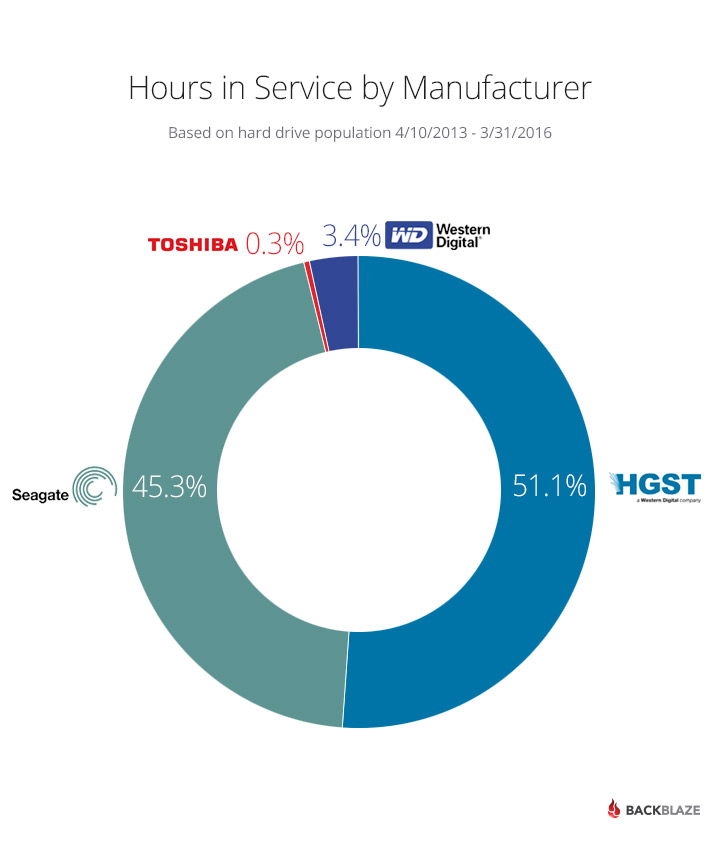
The early HGST drives, especially the 2- and 3TB drives, have lasted a long time and have provided excellent service over the past several years. This “time-in-service” currently outweighs the sheer quantity of Seagate 4 TB drives we have purchased and placed into service the last year or so.
Another way to look at drive hours is to see which drives, by size, have the most hours. You can see that in the chart below.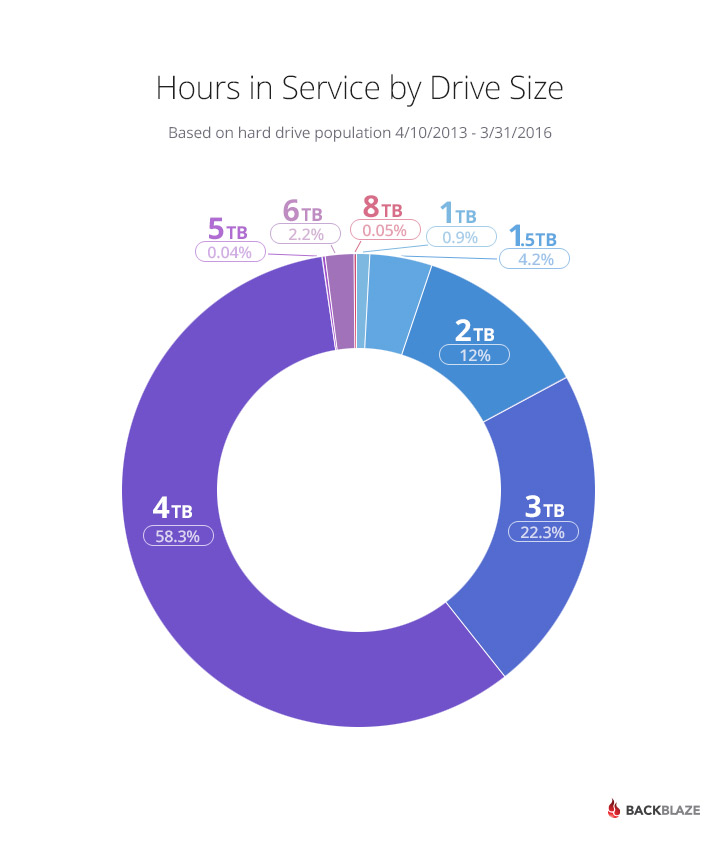
The 4TB drives have been spinning for over 580 million hours. There are 48,041 4TB drives which means each drive on average had 503 drive days of service, or 1.38 years. The annualized failure rate for all 4TB drives lifetime is 2.12%.
Hard Drive Reliability by Manufacturer
The drives in our data center come from four manufacturers. As noted above, most of them are from HGST and Seagate. With that in mind, here’s the hard drive failure rates by manufacturer, we’ve combined all of the drives, regardless of size, for a given manufacturer. The results are divided into one-year periods ending on 3/31 of 2014, 2015, and 2016.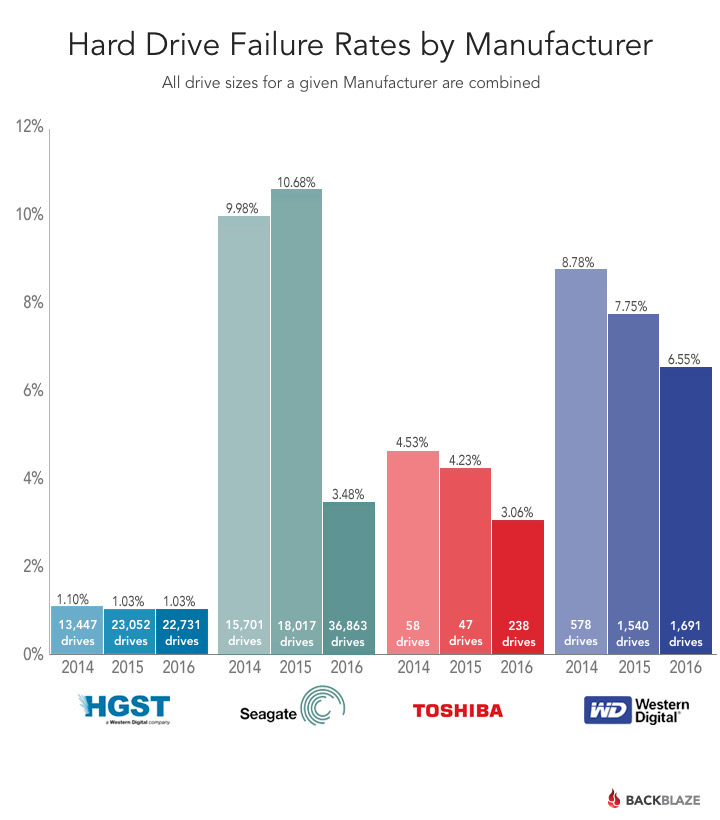
Why are there less than 45 drives?
A couple of times we’ve noted that we don’t display drive models with fewer than 45 drives. Why would we have less than 45 drives given we need 45 drives to fill a Storage pod? Here are few of the reasons:
- We once had 45 or more drives, but some failed and we couldn’t get replacements of that model and now we have less than 45.
- They were sent to us as part of our Drive Farming efforts a few years back and we only got a few of a given model. We needed drives and while we liked using the same model, we utilized what we had.
- We built a few Frankenpods that contained drives that were the same size in terabytes but had different models and manufacturers. We kept all the drives in a RAID array the same model, but there could be different models in each of the 3 RAID arrays in a given Frankenpod.
Regardless of the reason, if we have less than 45 drives of the same model, we don’t display them in the drive stats. We do however include their information in any “grand total” calculations such as drive space available, hours in service, failures, etc.
Buying drives from Toshiba and Western Digital
We often get asked why we don’t buy more WDC and Toshiba drives. The short answer is that we’ve tried. These days we need to purchase drives in reasonably large quantities, 5,000 to 10,000 at a time. We do this to keep the unit cost down and so we can reliably forecast our drive cost into the future. For Toshiba we have not been able to find their drives in sufficient quantities at a reasonable price. For WDC, we sometimes get offered a good price for the quantities we need, but before the deal gets done something goes sideways and the deal doesn’t happen. This has happened to us multiple times, as recently as last month. We would be happy to buy more drives from Toshiba and WDC, if we could, until then we’ll continue to buy our drives from Seagate and HGST.
What about using 6-, 8- and 10TB drives?
Another question that comes up is why the bulk of the drives we buy are 4TB versus the 5-, 6-, 8- and 10TB drives now on the market. The primary reason is that the price/TB for the larger drives is still too high, even when considering storage density. Another reason is availability of larger quantities of drives. To fill a Backblaze Vault built from 20 Storage Pod 6.0 servers, we need 1,200 hard drives. We are filling 3+Backblaze Vaults a month, but the larger size drives are hard to find in quantity. In short, 4TB drives are readily available at the right price, with 6- and 8TB drives getting close on price, but still limited in the quantities we need.
What is a failed hard drive?
For Backblaze there are three reasons a drive is considered to have “failed”:
- The drive will not spin up or connect to the OS.
- The drive will not sync, or stay synced, in a RAID Array (see note below).
- The Smart Stats we use show values above our thresholds.
Note: Our stand-alone Storage Pods use RAID-6, our Backblaze Vaults use our own open-sourced implementation of Reed-Solomon erasure coding instead. Both techniques have a concept of a drive not syncing or staying synced with the other member drives in its group
A different look at Hard Drive Stats
We publish the hard drive stats data on our website with the Q1 2016 results there as well. Over the years thousands of people have downloaded the files. One of the folks who downloaded the data was Ross Lazarus, a self-described grumpy computational biologist. He analyzed the data using Kaplan-Meier statistics and plots, a technique typically used for survivability analysis. His charts and analysis present a different way to look at the data and we appreciate Mr. Lazarus taking the time to put this together. If you’ve done similar analysis of our data, please let us know in the comments section below – thanks
